


Architektur für KI-Systeme
Ein Praxisbericht aus dem Finanzbereich von Mahbouba Gharbi und Dimitri Blatner
Mit dem Aufkommen datengetriebener Modelle sind KI-Komponenten längst fester Bestandteil produktiver IT-Systeme. Doch wie geht man architektonisch mit Systemen um, die autonome Entscheidungen treffen? Ein Kundenprojekt zur Analyse und Prognose von Finanzdaten zeigt, welche Herausforderungen dabei entstehen – und welche Lösungen sich bewährt haben.
Ausgangssituation und Zielsetzung
Im Projekt entwickelten wir eine Software zur automatisierten Bewertung von Finanzdaten. Ziel war ein System, das historische und aktuelle Kursdaten analysiert, Muster erkennt und daraus Prognosen ableitet – etwa die Wahrscheinlichkeit eines Kursanstiegs um mehr als fünf Prozent. Dazu konzipierten wir ein Zeitreihenmodell inklusive Datenstrategie, Feature-Engineering und Modellarchitektur. Für Klassifikationsaufgaben kamen zusätzliche Modelle zum Einsatz, insbesondere bei ungleichen/unausgewogenen Klassenverteilungen.
Die Integration in die bestehende IT-Landschaft stellte eine Herausforderung dar: Das Modell sollte leistungsfähig, skalierbar und nachvollziehbar sein. Zwar lieferte es präzise Vorhersagen, doch waren die Entscheidungsprozesse für Fachabteilungen zunächst schwer nachzuvollziehen – Rückverfolgbarkeit war gefragt.
Transparenz durch Rückverfolgbarkeit und Monitoring
Ein zentrales Ziel war es, Entscheidungswege des Modells transparent zu machen. Ein Reporting-Tool zeigte auf, welche Merkmale für eine Vorhersage maßgeblich verantwortlich waren. Der Fokus lag auf der Identifikation relevanter Einflussfaktoren, der Quantifizierung von Unsicherheiten und der Auswahl geeigneter Interpretationsverfahren.
Vertrauensmetriken: Unsicherheiten quantifizieren & Entscheidungen fundieren
Zur Verbesserung von Erklärbarkeit und Akzeptanz wurden Verfahren zur lokalen Modellinterpretation evaluiert. Besonders das SHAP-Verfahren (SHapley Additive exPlanations) erwies sich als geeignet. Durch Tree SHAP für Ensemble-Modelle erzielten wir eine gute Balance zwischen Erklärqualität und Laufzeit. Unter bestimmten Bedingungen konnte z. B. der gleitende Durchschnitt der letzten 30 Tage als dominanter Einflussfaktor identifiziert werden.
Vertrauensmetriken quantifizierten die Unsicherheit von Modellvorhersagen, ohne die Systemperformance zu beeinträchtigen. Sie basierten auf Konfidenzintervallen und Wahrscheinlichkeitsverteilungen. Eine Prognose von +10 %, bei tatsächlichem Anstieg von nur 5 %, wurde als unsicher markiert.
Heatmaps visualisierten diese Metriken: Farbcodierte Darstellungen hoben kritische Datenpunkte hervor, Unsicherheiten wurden auf einen Blick sichtbar. Fachabteilungen konnten so auf risikobehaftete Vorhersagen gezielt reagieren.
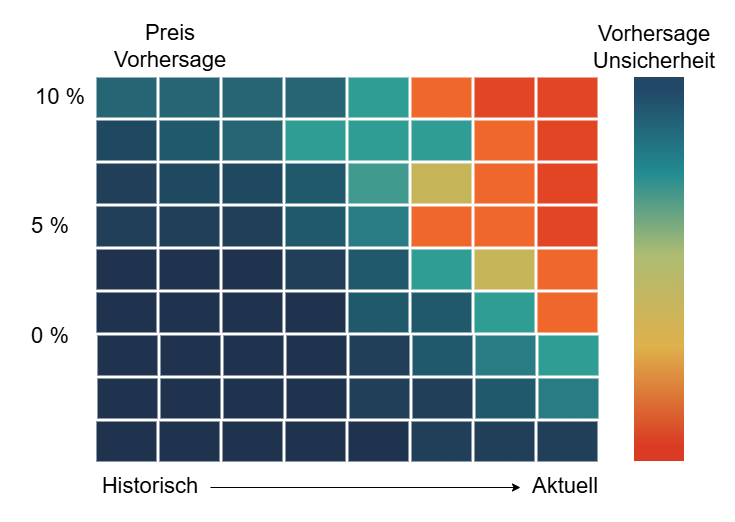
Abbildung 1: Heatmap
Monitoring-System: Überwachung und Anomalie-Erkennung
Ein mehrstufiges Monitoring-System sicherte die Verlässlichkeit und Funktionsfähigkeit des Modells im laufenden Betrieb:
- Drift Detection: Datenverschiebungen erkennen (z. B. durch Zinserhöhungen, politische Ereignisse)
- Performance Monitoring: Bewertung von Kennzahlen wie Genauigkeit, Latenz, F1-Score – Dashboard mit Echtzeitüberwachung
- Fehleranalyse: Sammlung und Analyse kritischer Entscheidungen zur Modelloptimierung
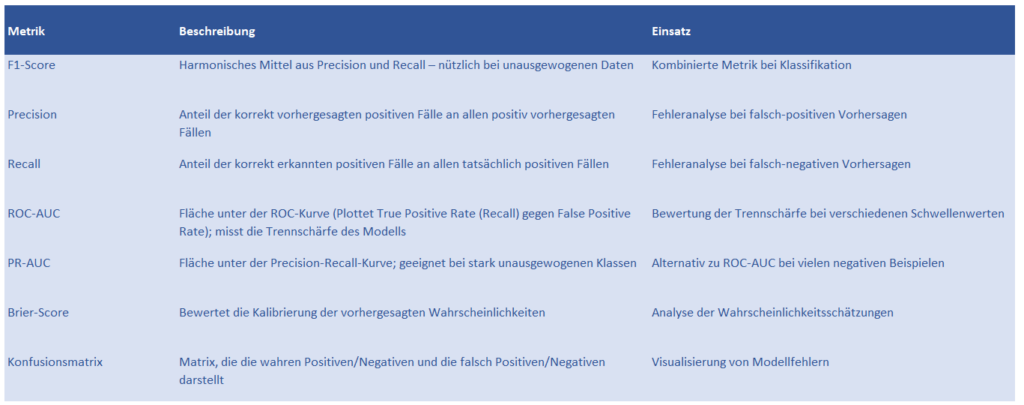
Abbildung 2: Technische Qualitätsmetriken
Entscheidungen wurden als kritisch eingestuft, wenn sie deutlich vom tatsächlichen Ergebnis abwichen oder der F1-Score <0,75 lag. Ein Analysetool sammelte Datenpunkte, um Modelle gezielt weiterzuentwickeln. Zusätzlich kamen AUC-Werte sowie der Brier-Score zur Kalibrierung zum Einsatz. Eine Konfusionsmatrix unterstützte die Fehlereinordnung. Ergänzend wurden geschäftsrelevante Metriken wie Trefferquote bei Kursanstiegen >5 %, erwarteter Gewinn pro Trade, Sharpe Ratio sowie maximaler Drawdown einbezogen. Die Verbindung aus technischer und wirtschaftlicher Analyse ermöglichte eine fundierte Bewertung der Modellgüte.
 Abbildung 3: Geschäftsrelevante Bewertungsgrößen
Abbildung 3: Geschäftsrelevante Bewertungsgrößen
Anonymisierung und Schutz der Eingangsdaten
Die Verarbeitung sensibler Finanzdaten erforderte strikte Maßnahmen. Die Datenpipeline anonymisierte Namen und Kontodaten und nutzte verschiedene Verfahren wie Generalisierung, Pseudonymisierung sowie Verschlüsselung. Differential Privacy minimierte Reidentifikationsrisiken und unterstützte die Einhaltung regulatorischer Anforderungen.
Technische Umsetzung: Modellversionierung und Rückfallebene
Ein wichtiger Baustein war die Modellversionierung: Im Unterschied zur klassischen Softwareversionierung dokumentierten wir zusätzlich Trainingsdaten, Hyperparameter und Evaluationsmetriken. Ein Modellregister speicherte sämtliche Versionen inklusive der jeweils verwendeten Metadaten und Hyperparameter. Bei Fehlern griff eine Rückfallebene mit einfachen, regelbasierten Berechnungen, um kritische Entscheidungen abzusichern.
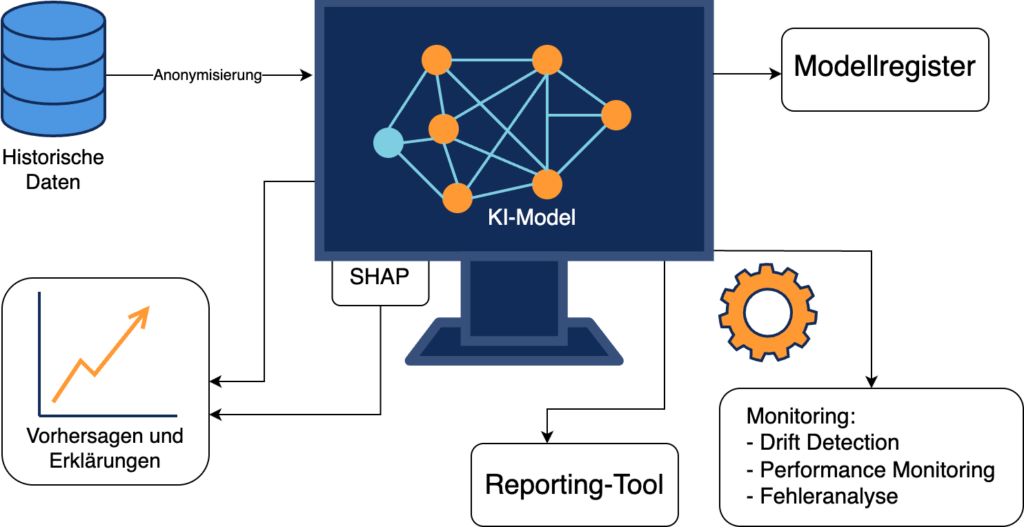
Abbildung 4: Schema der technischen Umsetzung
Lessons Learned: Architektur als Verantwortung
Die Integration von KI erfordert vorausschauende Planung, Teamkommunikation und Disziplin. Zieldefinition, Datenstrategie und Systemarchitektur müssen frühzeitig aufeinander abgestimmt sein. Unser Projekt zeigte: Datenschutz, Rückverfolgbarkeit, Vertrauensmetriken und Fehleranalysen entscheiden über Akzeptanz und Zuverlässigkeit. KI ist kein Selbstzweck – erst im Zusammenspiel mit fundierter Architektur, interdisziplinärer Zusammenarbeit und kontinuierlicher Qualitätssicherung entsteht ein robustes, verantwortbares System.
KI-Architektur heißt: gestalten, erklären, absichern – und laufend nachjustieren.
Über die Autoren:
Mahbouba Gharbi ist Geschäftsführerin, Softwarearchitektin und Trainerin bei ITech Progress GmbH, einem akkreditierten Schulungsanbieter des iSAQB®, mit über zwanzig Jahren Erfahrung. Als Kuratorin des iSAQB-Moduls SWARC4AI vermittelt Mahbouba methodische und technische Konzepte für den Entwurf und die Entwicklung skalierbarer KI-Systeme an IT-Professionals und legt dabei besonderen Wert auf praxisnahe und nachhaltige Lösungen.
Dimitri Blatner ist Softwarearchitekt und Trainer bei ITech Progress GmbH. Als zertifizierter Trainer für SWARC4AI vermittelt Dimitri praxisnahes Wissen für den Entwurf und die Entwicklung skalierbarer KI-Systeme. Dimitris Schwerpunkte liegen auf Cloud-Technologien, DevSecOps, hybriden Architekturen und KILösungen und er unterstützt Unternehmen bei der Realisierung innovativer und sicherer Systeme.







